Problem Statement:
To use the Raw Data (CSV and JSON files) regarding Formula1 from Ergast API to provide useful information. To implement ingestion, transformation, reporting, analysis, and scheduling with Azure Databricks.
GitHub
Tools and Technologies:
- Azure Data Bricks, PySpark, Spark SQL, Azure Key Vault, DBFS, Azure Data Lake Storage Gen2, DataFrames, DeltaLake
Summary:
- Created new instances of Azure Key Vault, ADLS G2, and Azure Databricks.
- Mounted ADLSG2 using DBFS utilities.
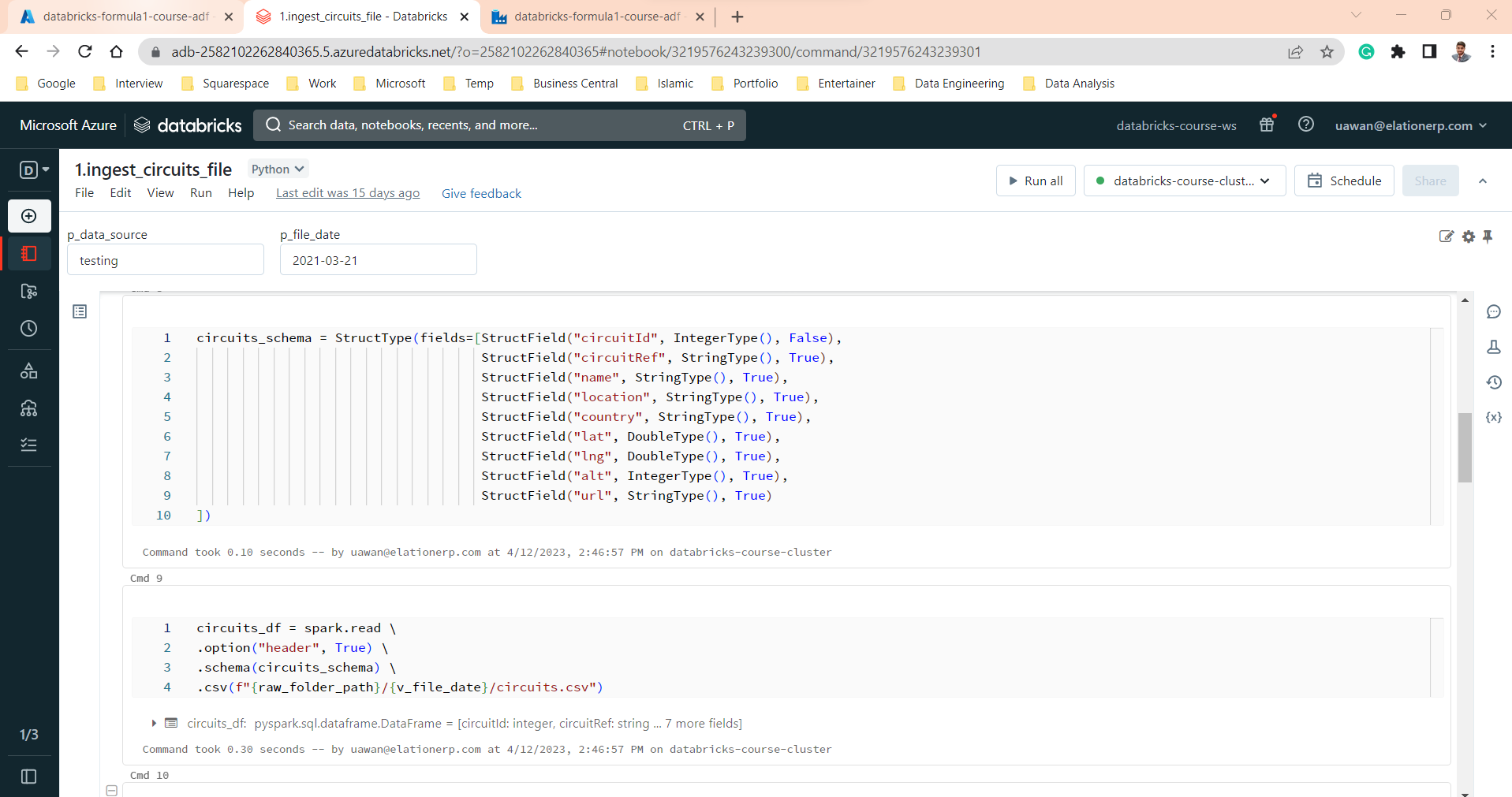
- Picked raw data of all 8 files by creating the schemas for Data frames.
- Renamed and transformed the columns before ingestion.
- Handled the reloading and incremental reload.
- Stored the data in Delta Tables. Also tested by saving data in Parquet format.
- Created driver standings and Constructor standings report using Spark SQL.
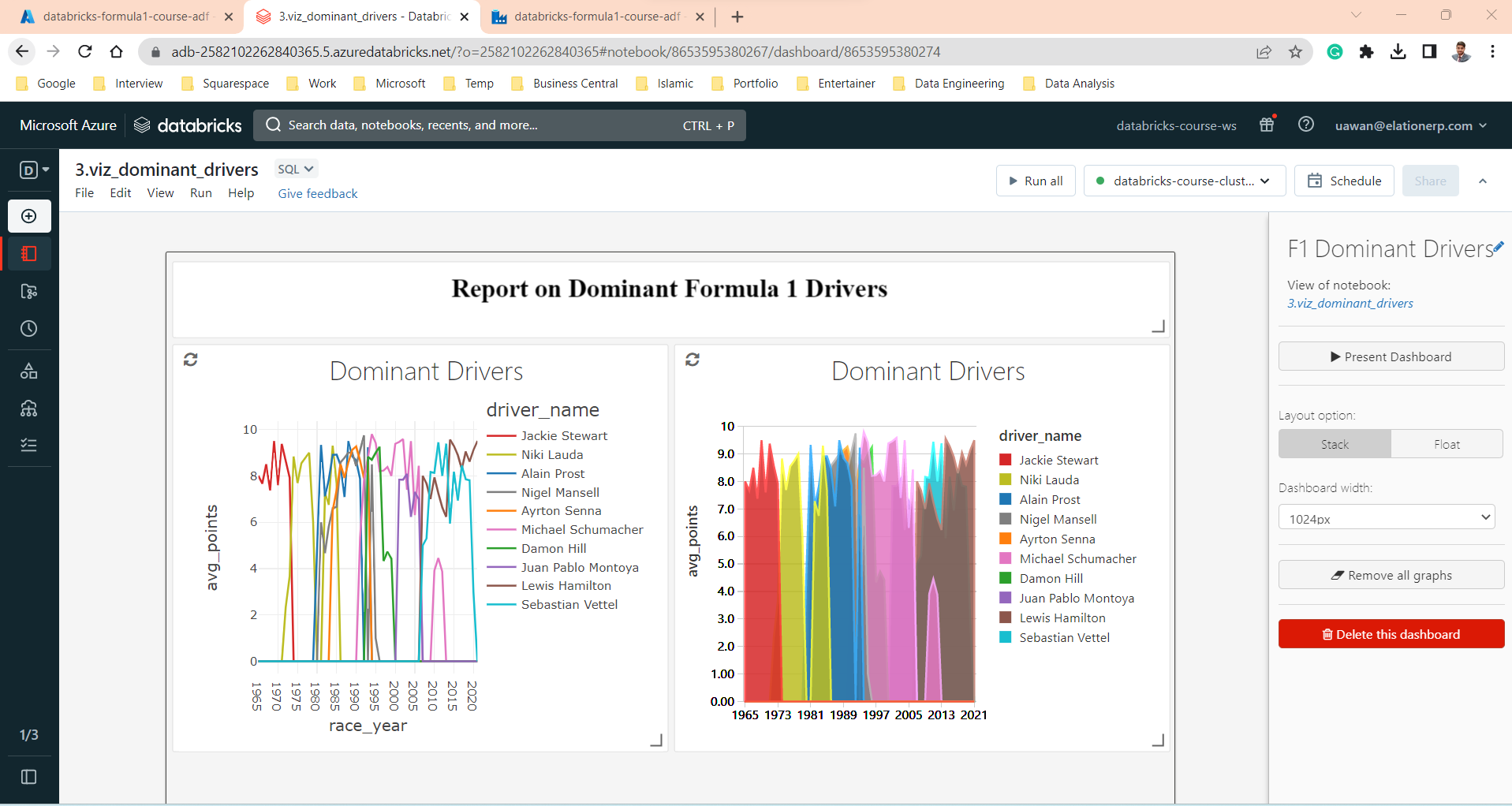
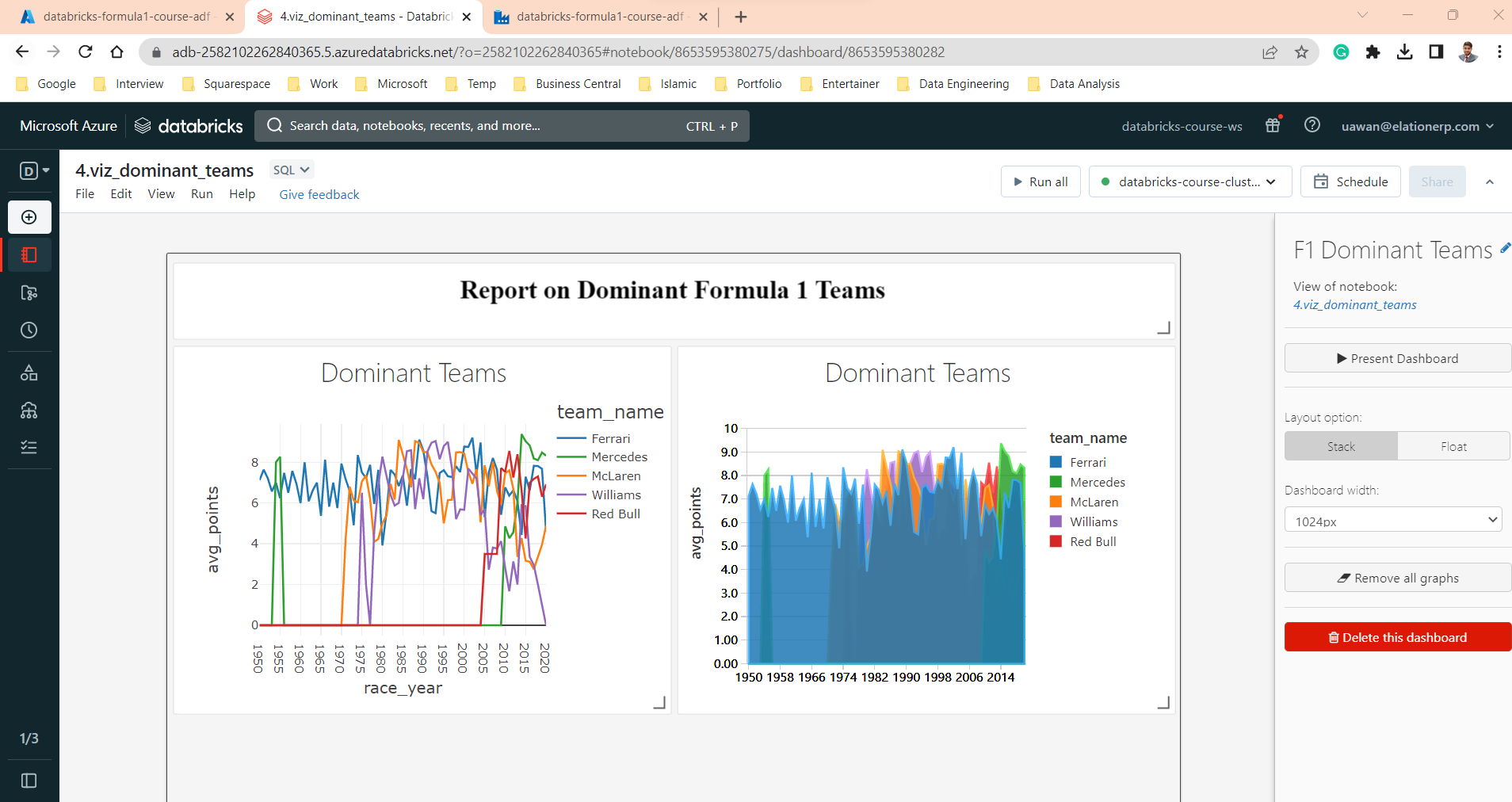
- Created visualizations for Dominant drivers and Dominant Teams in Notebooks by using SQL. Also created the dashboard in Databricks.
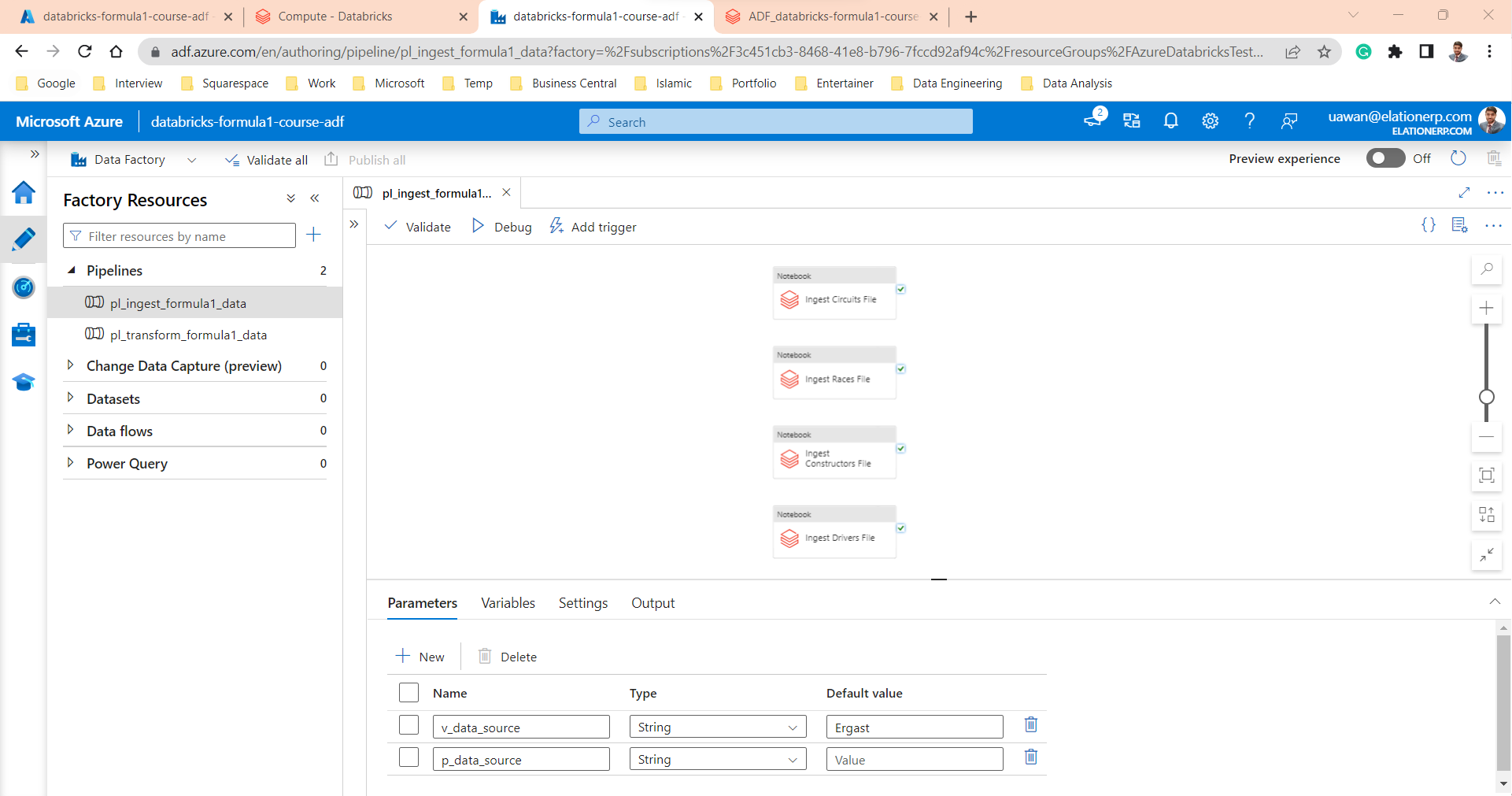
- Scheduled the ingestion notebooks with pipelines in Azure Data Factory.
- Used joins, and filters for aggregation in PySpark and Spark SQL.
- Used Managed and External tables for saving the data.
- Tested the time travel, history, and vacuum in DeltaLake.